上期回顾:
今天给大家推荐一个Gtihub开源项目:PythonPlantsVsZombies,翻译成中就是植物大战僵尸。
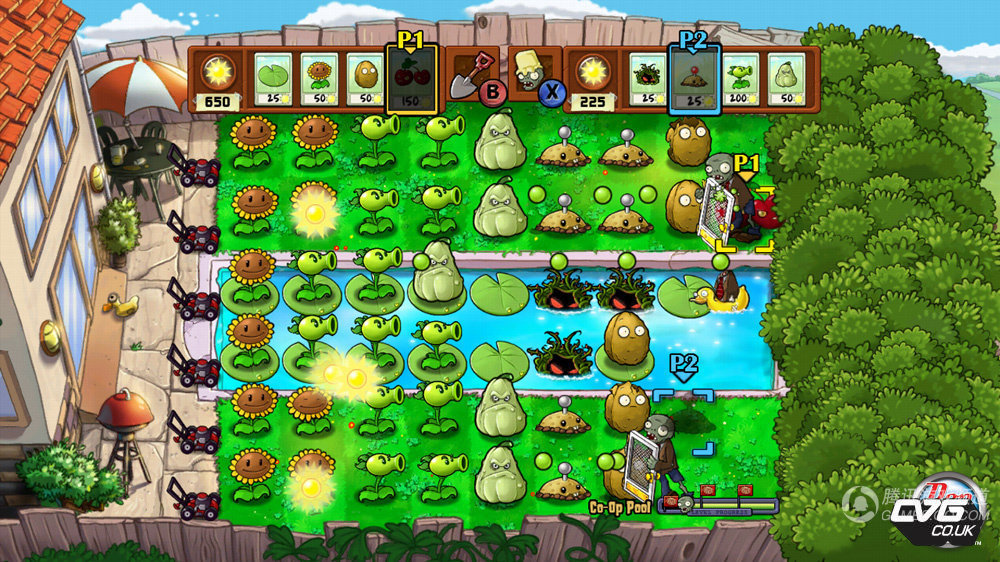
《植物大战僵尸》是一款极富策略性的小游戏。可怕的僵尸即将入侵,每种僵尸都有不同的特点,例如铁桶僵尸拥有极强的抗击打能力,矿工僵尸可以挖地道绕过种植在土壤表面的植物等。玩家防御僵尸的方式就是栽种植物。49种植物每种都有不同的功能,例如樱桃炸弹可以和周围一定范围内的所有僵尸同归于尽,而食人花可以吃掉最靠近自己的一只僵尸。玩家可以针对不同僵尸的弱点来合理地种植植物,这也是胜利的诀窍。游戏根据玩法不同分为五种游戏模式:冒险模式、迷你模式、解谜模式、生存模式、禅境花园。加之黑夜、屋顶、浓雾以及泳池之类的障碍增加了其挑战性。该游戏近乎永无止境。

文章地址:Python版【植物大战僵尸 +源码】
写在前面:
大家好,很高兴再次与大家相聚在这里。继上一篇关于使用Python实现植物大战僵尸的文章之后,我收到了许多热情的回复和积极的反馈。在众多评论中,我发现许多小伙伴对于将机器学习技术应用于游戏开发表现出了浓厚的兴趣。为了回应大家的期待,今天我将为大家带来一篇全新的内容——探索如何将机器学习技术融合到植物大战僵尸游戏中,实现AI植物大战。
今天,我就为大家带来了机器学习赋予游戏行业的案例——通过融合机器学习算法的智能Python版的植物大战僵尸。在这篇文章中,我们将深入探讨Python语言和机器学习实现植物大战僵尸的原理,并对代码进行详细的分析和讲解。相信这篇文章都能给你带来不少启发和收获。
在这篇文章中,我们将一起深入探讨如何利用Python语言结合机器学习算法,来增强植物大战僵尸游戏的智能性和互动性。无论你是游戏开发的爱好者,还是对人工智能充满好奇的探索者,相信这篇文章能够为你提供丰富的知识和灵感。让我们一起开启这场关于游戏开发与人工智能相结合的奇妙旅程吧!
一、环境准备:
-
Python版本:
- Python 3.7
-
Python库:
-
开发环境:
- 集成开发环境(IDE):推荐使用如PyCharm,它提供了代码编辑、调试和可视化工具,有助于提高开发效率。
- 版本控制:使用Git进行版本控制,可以帮助管理代码变更和协作开发。
-
硬件要求:
二、游戏内容:

2.1、 游戏目标:
玩家的目标是在僵尸不断进攻的情况下,保护好房间不被僵尸闯入。玩家需要策略性地种植各种植物来抵御僵尸的进攻。
2.2 、植物卡牌系统:
- 游戏的左侧设有一个滚轮机会,它会不断地随机生成各种植物的卡牌。
- 玩家可以通过鼠标点击来选中想要的植物卡牌,选中的植物卡牌会显示高亮或改变颜色,表示已被激活。
- 当植物被选中后,鼠标指针会变成该植物的图标,并且可以移动到草地的任何位置进行放置。
- 再次点击鼠标或空格键,玩家可以将选中的植物种植在指定的草地上,建立起防御阵线。
import random
from collections import namedtuple
# 定义植物卡牌类
PlantCard = namedtuple('PlantCard', ['name', 'image', 'cost', 'effect'])
# 初始化植物卡牌列表
plant_cards = [
PlantCard('Peashooter', 'peashooter_image.png', 100, 'Shoots peas at zombies'),
PlantCard('Sunflower', 'sunflower_image.png', 50, 'Generates sun points over time'),
# ... 其他植物卡牌
]
# 随机生成植物卡牌滚轮
def generate_card_roulette():
return random.choice(plant_cards)
# 玩家选择植物卡牌
def select_plant_card(card_roulette):
selected_card = generate_card_roulette()
# 这里可以添加代码来高亮或改变选中卡牌的颜色
return selected_card
# 玩家放置植物到草地
def place_plant(selected_card, position):
# 将植物放置到指定位置的逻辑
# 这里可以添加代码来改变鼠标指针图标,并在草地上放置植物
pass
2.3 、植物功能介绍:

- 豌豆射手:基础攻击植物,可以发射豌豆攻击前方的僵尸。
- 寒冰射手:发射冰冻豌豆,不仅能攻击僵尸,还能减缓僵尸的移动速度。
- 三头豌豆射手:同时发射三颗豌豆,具有更强的攻击力。
- 坚果:具有高耐久性,可以阻挡僵尸前进,为其他植物争取攻击时间。
- 吹风草:具有特殊能力,可以一次性将所有屏幕上的僵尸吹出屏幕。
- 地刺:放置在草地上后,会对经过的僵尸造成持续伤害。
2.4 、僵尸介绍:
-
游戏中有多种类型的僵尸,每种僵尸都有不同的血量和移动速度。

-
击杀特定类型的僵尸,如足球僵尸,可以获得随机奖励,这些奖励会对僵尸产生特殊效果,如全屏僵尸死亡或全屏僵尸静止两秒等。
2.5 、游戏互动:
- 如果玩家对放置的植物不满意,可以使用铲子图标移除已种植的植物,为重新布局防御提供灵活性。
- 游戏过程中,玩家需要注意植物的阳光产出,阳光是种植植物的货币,合理管理阳光资源对于建立有效的防御至关重要。
2.6 、游戏结束与重新开始:
三、植物大战僵尸融合机器学习实现:
要将机器学习融入植物大战僵尸游戏中,我们需要构建一个能够理解游戏环境、做出决策并从中学习的智能体。以下是实现这一目标的核心代码的丰富和优化版本:
-
游戏环境模拟:
- 创建一个模拟植物大战僵尸游戏环境的类,该类负责管理游戏状态、执行动作并提供反馈。
- 定义状态空间,例如游戏中的植物布局、僵尸位置、阳光数量等。
- 定义动作空间,例如选择植物卡牌、放置植物、收集阳光等。
- 设计奖励函数,根据智能体的行为给予正面或负面的奖励。
class GameEnvironment: def __init__(self): # 初始化游戏状态 self.plants = [] self.zombies = [] self.sun = 0 # ... 其他初始化代码 def reset(self): # 重置游戏状态 # ... def step(self, action): # 执行动作并更新游戏状态 # ... return next_state, reward, done, info def render(self): # 渲染游戏界面,用于观察和调试 # ... -
强化学习代理:
- 开发一个强化学习代理,它使用神经网络或其他函数近似器来学习最优策略。
- 实现一个深度Q网络(DQN)或演员-评论家(Actor-Critic)模型,以处理高维输入和连续动作空间。
- 使用经验回放机制和目标网络来提高学习稳定性。
class DQNAgent: def __init__(self, state_space, action_space, network=None): self.state_space = state_space self.action_space = action_space self.network = network or self.create_network() self.memory = ReplayMemory() def create_network(self): # 创建神经网络模型 # ... def choose_action(self, state): # 使用ε-greedy策略选择动作 # ... def learn(self, experiences): # 从经验中学习,更新网络权重 # ... class ReplayMemory: def __init__(self, capacity): self.memory = deque(maxlen=capacity) def store(self, experience): # 存储经验 # ... def sample(self, batch_size): # 随机采样一批经验 # ... -
游戏模拟与训练循环:
- 实现一个训练循环,智能体在游戏环境中不断尝试不同的策略,并通过机器学习模型进行自我改进。
- 使用探索策略(如Boltzmann探索)来平衡探索和利用。
- 定期评估智能体的性能,并在达到预定性能指标后停止训练。
def train_loop(agent, environment, num_episodes): for episode in range(num_episodes): state = environment.reset() total_reward = 0 done = False while not done: action = agent.choose_action(state) next_state, reward, done, _ = environment.step(action) total_reward += reward experience = (state, action, reward, next_state, done) agent.memory.store(experience) state = next_state agent.learn(agent.memory.sample(batch_size)) if episode % 100 == 0: print(f'Episode {episode}: Total reward = {total_reward}') -
游戏AI的集成:
def play_game_with_ai(ai_agent, environment): state = environment.reset() while True: action = ai_agent.choose_action(state) state, _, done, _ = environment.step(action) if done: break
这些代码提供了一个基本的框架,用于开发和训练一个能够在植物大战僵尸游戏中自主决策的智能体。在实际应用中,你需要根据游戏的具体规则和API进行调整,并可能需要使用更高级的机器学习技术和算法。此外,为了提高智能体的性能和学习效率,你可能还需要考虑多智能体学习、迁移学习等更复杂的策略。
四、机器学习给游戏行业带来的机遇和挑战
随着机器学习技术的飞速发展,游戏领域正迎来一场革命性的变革。这项技术不仅为游戏设计师提供了新的工具来创造更加丰富和动态的游戏体验,也为玩家带来了前所未有的个性化和互动性。通过机器学习,游戏AI能够学习玩家的行为模式,适应并提供更具挑战性的游戏环境,同时个性化推荐系统能够根据玩家的喜好量身定制游戏内容,极大地提升了游戏的吸引力和留存率。

然而,这些进步也伴随着一系列挑战。机器学习模型的构建和训练需要大量的数据和计算资源,这对游戏开发者提出了更高的技术要求。同时,如何确保玩家数据的隐私和安全,以及如何处理由此产生的伦理和责任问题,也成为了游戏产业必须面对的重要议题。此外,智能AI可能会对游戏平衡产生影响,开发者需要精心调整,以保持游戏的趣味性和公平性。
尽管存在挑战,但机器学习为游戏领域带来的机遇是巨大的。它不仅能够提升游戏的娱乐价值,还能够推动游戏产业的技术创新和经济增长。未来,我们有望看到更多融合了机器学习技术的游戏作品,它们将不断突破传统的游戏设计界限,为玩家带来更加沉浸和智能的游戏体验。同时,游戏开发者、玩家和整个社会也需要共同努力,确保这些技术的发展能够负责任地进行,为所有人创造一个更加安全和包容的游戏环境。